
Architecture: Data persistence design layer
Demonstration In-memory database
The implementations of LoggingServiceAPI and AdminServiceAPI are implemented by DemonstrationLoggingService and DemonstrationAdminService respectively. The demonstration services make use ofcst.common.persistenceLayer.DemonstrationDB, which manages instances of the data container classes described in the
business concept layer.
Figure Arch-Persistence-1 shows how these classes relate.
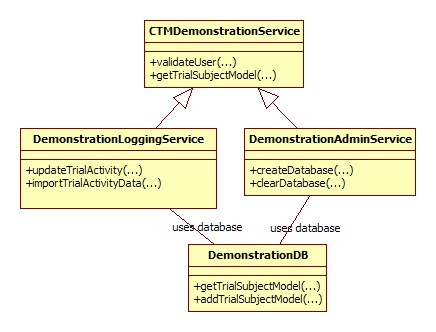 Figure Arch-Persistence-1: Classes used to support demonstration services
Figure Arch-Persistence-1: Classes used to support demonstration services
The cloning mechanism supported in the model classes allows the demonstration services to support notions of master and copy records. Master and copy records are used to support an artificial kind of persistent storage which only lasts until the users close the tools.
The implementation of the production services is complicated enough to warrant having ProductionLoggingService and ProductionAdminService rely on delegation classes. For the implementation of the demonstration services, the code is much simpler and no such delegation classes are used.
Production MySQL database
cst.common.persistenceLayer.SetupProductionDatabase is the class responsible for creating a relational database for the data model described in the configuration file.
Most of the code related to SQL operations appears in:
cst.loggingTool.persistenceLayercst.adminTool.persistenceLayer
The next section describes the relational schemas that CST generates. This discussion is followed by a review of the code used to manage SQL operations.
Relational database schema
CST uses properties in the configuration file to generate a relational database. The following tables are generated:- a table to describe trial subjects
- a table to describe users
- a table to record changes made to activity data for each trial subject
- a table for each activity
Data modellers can specify the names of these tables as appropriate for their use cases. The entity-relation diagram below is an example of the kind of database schema which is generated.
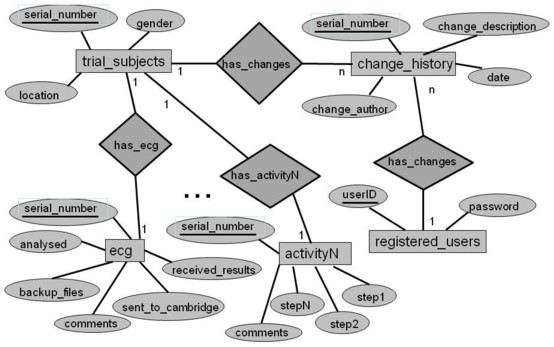
The names of all tables are specified in a configuration file. The following fields shown in the diagram are reserved fields that are hard-coded in the application:
-
all the fields in
change_historyexceptserial_number, which is the name of the primary key that appears for most of the entities. -
all fields in
registered_users -
the
commentsfield which appears in each activity.
The extensibility of the schema generated is shown in activityN. The model is a star schema where the trial subjects table is at the centre and where the activity tables are spokes. These tables are linked using the same primary key (serial_number in the example). The primary key field is a VARCHAR type whose length can be parameterised from the primary_key_length tag in the configuration file.
The change_history and registered_users tables are linked with the fields change_author and userID.
The primary keys are all indexed to promote better performance in executing queries.
Classes for handling SQL code
The MySQL implementations of LoggingServiceAPI and AdminServiceAPI and are implemented by ProductionLoggingService and ProductionAdminService respectively. Figure Arch-Persistence-2 illustrates how the production service implementations delegate to other classes.ProductionLoggingService and ProductionAdminService are delegation classes
which are responsible for three main tasks:
- validate users
- assign and reclaim database connections
- apply rollback and recovery when errors occur
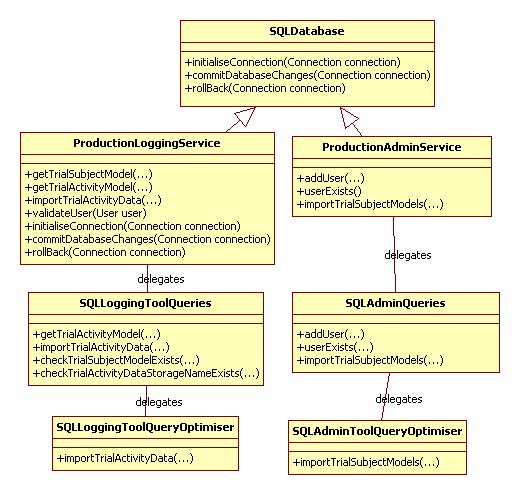
Figure Arch-Persistence-2: Delegation classes in the MySQL implementation
For example, ProductionLoggingService implements the interface
LoggingServiceAPI and is instantiated to make the
MySQL implementation of the logging service. The following is an example of the steps that ProductionLoggingService
follows for importTrialActivityData(...).
- validate user
- obtain a connection from the connection pool manager
- initialise the database connection (turn auto-commit off so database accumulates the results of applying one or more commands in succession)
- delegate business operation to the
SQLLoggingToolQueriesclass, which actually executes SQL commands. - if the operation did not result in any errors, let the database connection commit changes to the database.
- if the error did produce any errors, then rollback the database to the state it had before the operation was executed
Note that the steps for initialising, committing changes and rollback are only used in operations that are trying to change the database. Operations that only retrieve data don't require management of MySQL's rollback and recovery mechanisms.
SQLLoggingToolQueries is responsible for executing SQL queries and marshalling data between SQL constructs and instances of data container classes that are defined in the business concept layer.
A typical method in this class will follow these steps:
- create a query string containing question marks for parameters that will be filled in by the data in the actual parameters.
-
use the query string to create a
PreparedStatement. -
execute the
PreparedStatement - catch any errors thrown in the code. If any errors do occur, create an instance of CSTException and initialise it with an informative error message. Then throw the exception.
-
use a
finallycode block to close any statement or result set objects.
For some methods such as importTrialActivityData(...), SQLLoggingToolQueries delegates to a third class SQLLoggingToolQueryOptimiser. This class is designed to rewrite certain methods in SQLLoggingToolQueries which may show performance problems.
The importTrialActivityData(...) method does bulk import of data and has become a good candidate for code optimisation. Optimised code has been consolidated in the optimizer class to make the rest of the code more readable.
Author: Kevin Garwood
(c)2010 Medical Research Council. Licensed under Apache 2.0.