
Project History
by Sheila Raynor
A clinical study for the National Survey of Health and Development
The Clinical Study Tracker (CST) was a software solution created in response to a need to log and track large amounts of clinical data that were being processed during a three year clinical research study (2007-2010) conducted by the Lifelong Health and Ageing Unit (LHA) of the Medical Research Council (MRC). The LHA is home to the National Survey of Health and Development (NSHD), an ongoing British birth cohort study initially of 5362 men and women born in England, Scotland or Wales in March 1946. For more information about the LHA and NSHD, click here. During this NSHD clinical study, approximately 2000 of the original 5362 participants were expected to participate in a series of 5 different cardiovascular measurements performed during a single clinic appointment. Six partner clinical research facilities based around the United Kingdom (UK) were recruited to carry out the measurements, with the LHA coordinating, analysing, and storing all of the test results in a data library.The raw medical data collected at the research facilities would be sent to the coordinating centre where I was based. My job was to manage the logistics of the incoming data which required logging, followed by either external scientific analyses off-site or post processing in-house. This meant that the data not only needed to be logged once, but multiple times as it moved in and out of the coordinating centre during multiple processing steps with it eventually reaching the data library.
In addition to tracking large amounts of medical data during the study, my job was to also maintain quality control of the data as it arrived from the participating research facilities to ensure good quality raw data during the study. This meant opening up every file to access the overall data quality.
Motivation for tracking each test conducted on every participant
My job of tracking test data against 2000 study participants would have been simplified if the tests conducted would have all been treated in a similar manner and arrived at the same time at the coordinating centre. However, a number of factors required me to separately track each of the separate 5 tests done on every participant:- The raw data from each test came from a different piece of medical equipment and therefore the format and file type of the data varied widely. This meant separate processing for each type of test in order to obtain the end test results for the data library. For example, some of the data arrived a DICOM (Digital Imaging and Communications in Medicine) files on a CD, other data arrived on encrypted memory sticks as a series of EXCEL files, or CSV (comma separated values) downloaded directly from the medical equipment.
- Some tests required off-site scientific analyses by our partner ‘reading centres’ in order to obtain the end test results. This required data to be batched up and sent off-site for several months at a time.
- Other tests were post-processed in-house but also had various stages to the process before end test results were obtained.
- Sometimes we could not conduct all of the tests on each participant due to medical reasons. This needed to be noted, so we would not be looking for ‘missing data’. Therefore, we added a comments box on the software tool.
- Our data was confidential so good tracking with an audit trail was important.
- Some data files needed to be returned to the clinical research facility due to downloading errors. Therefore various test data for a participant may arrive at the coordinating centre weeks apart.
- We needed to know at what stage of the process each individual test was for every participant since multiple process steps were involved to obtain the end test results for the data library.
Identifying steps in the tracking activities
Although we had to separately date track the medical tests (ECHO, IMT, HRV, PWV and PWA), the steps of each task shared some similarities. Specifically we focused on tracking the following data:- Date of arrival of test from remote clinical research facility to coordinating centre (logged against participant’s identification number)
- Date the test was sent to scientific ‘reading centre’ (ECHO, IMT, HRV)
- Date the test was received back from the ‘reading centre’
- Date the test was sent to Data Management Group for processing in-house
- Date the test was successfully extracted in-house from Excel or CSV files by the Data Management Group
- Date the test was successfully uploaded into the Data Library
More work beyond making 50,000-60,000 date entries
When I was working at the LHA, I was the sole person responsible for tracking the progress of cardiovascular tests from origination at the clinical research facility through to ensuring the end results could be uploaded into the data library. My initial calculation for the work needed to track subjects assumed that there would be no errors in the way data were collected, analysed or post-processed. The initial work estimate also didn’t consider delays caused by the LHA or its any of its partner sites. The following challenges of coordinating efforts with other partners complicated the tracking activity:- Tests for each participant did not all arrive simultaneously at the coordinating centre on a timely basis
- Some tests were incomplete and needed to be returned to the clinical research facility
- Some device operators were relatively inexperienced at performing the tests and their results needed to be carefully checked
- CD’s failed and needed to be recopied
- Only partial test results would be sent to the centre, with no explanation about the missing data
- Some staff had difficulty downloading data onto the encrypted memory sticks
- the staff forgot to SAVE the file after the test, or into the correct file format requested by the coordinating centre
- Medical devices broke, and were sent away for repair resulting in missing data
Thus my job was not simply to track the results, but to also perform quality assurance tests on the data we did process and deal with rectifying any errors. I had to make a decision about how much time I invested in tracking data. Although there were five cardiovascular tests for each volunteer, each test result was expressed as hundreds of data points which had to be vetted before the whole result could be accepted or rejected. It was becoming impractical for me to both perform quality assurance tests on the test data and track them as well. Quality assurance activities represented what I will call the MICRO management of the cardiovascular data.
My job became even more complicated when it was requested that I should provide interim progress reports on our cardiovascular data collection and processing. At monthly meetings of the Cardiovascular Project Management board, I had to update board members with results which could include information such as:
- Amount of cardiovascular data successfully acquired by the remote clinical research facilities to date
- What stage in the processing were each of the 5 tests
- Where a time lag or bottleneck may be occurring,
- Missing data
- Notification when the data was complete and in the data library so that academic papers could be written.
I knew that this was only the beginning of the progress reports, since there were many stakeholders in this data who all wanted to know where we were with such a complex data collection. Given my work load and the fact I was the only person charged with managing the cardiovascular data, it was becoming impractical for me to manually check, track and report on the test data for all 2000 participants. I began to consider ways that my work could be automated.
Quality assurance checks could not be automated because results had to be visually inspected by someone with specialist knowledge. MACRO management of the data such as date tracking the movement of the files did not require specialist knowledge, but was a critical step nonetheless for the study. I believed that the process of date tracking could indeed be automated in such a way so that relatively unskilled user could be quickly trained to log the dates with a minimal amount of errors. These users could even produce progress reports if needed if the software worked effectively.
The need for software to support tracking a clinical study
When I joined the study, there were no systems in place to track the cardiovascular tests which were already being received from the remote clinical research facilities. Using pen and paper would not have been scalable for tracking large numbers of participants through many various medical tests and subsequent data processing. Using an Excel spreadsheet to track the projected 50,000-60,000 entries would have been very error-prone. It would also not have retained an audit trail of updates made by multiple end-users.
I decided that the software application could MACRO manage tracking test data. Therefore, I began sketching out the idea for an in-house software tool which would let me track the participants and their data. I began by making a schematic drawing which included each of the medical tests (ECHO, IMT, HRV, PWA, PWV) I was responsible for and needed to track. For each medical test I identified the key individual processing steps which began with the initial acquisition at the remote clinical research facility and ended with uploading data to the LHA’s data libraries.
I designed the schematic to represent the processing steps in the simplest manner for each of the 5 medical tests. The process steps could be represented by a field name (name of the medical test) and a completion date for each individual process step. I created some sample output graphs which would show the progress of work done. I based the sample graphs on what I was already being asked to provide to the stakeholders, but was taking an enormous amount of time to generate.
Below are the scribbles which led to the first idea for CST:


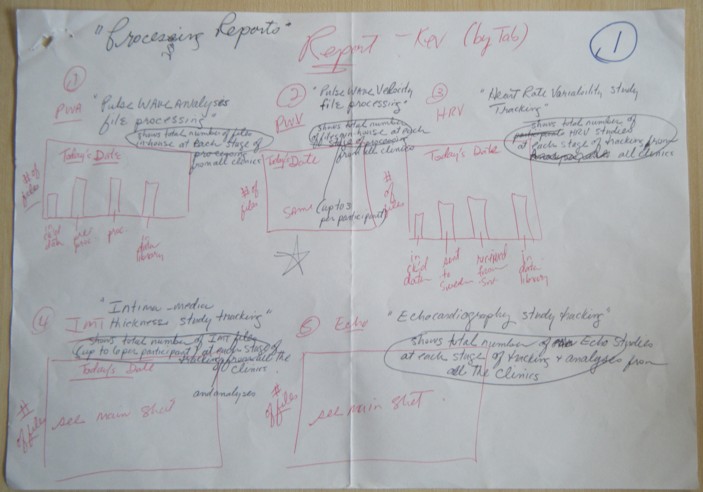


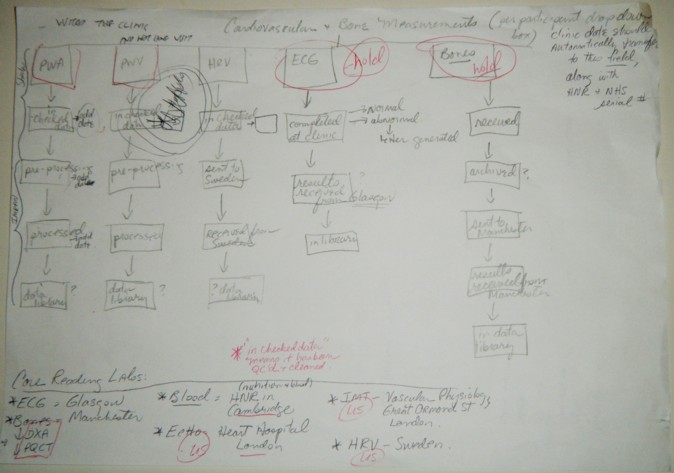
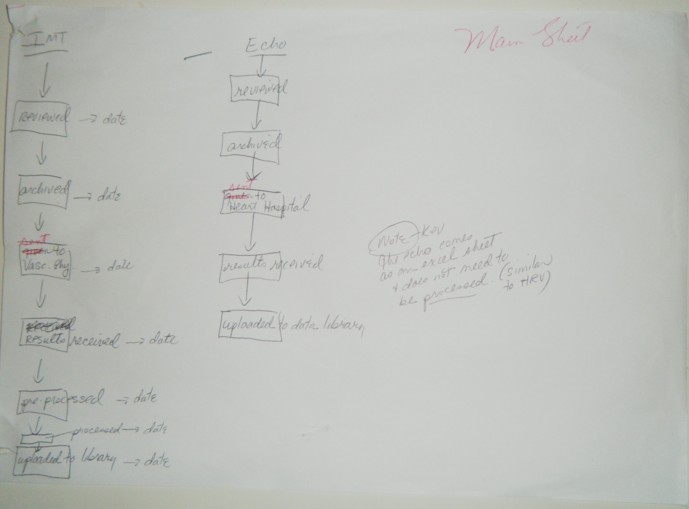
I took the schematics to Kevin Garwood, who is the main developer of the LHA’s Data Services Group (DSG). He noted that the simplicity of the features suggested that the application could be generated from a configuration file. Kevin asked me to use my past experience dealing with clinical trials to answer three important questions:
- What is the minimal set of features that would be needed by the LHA to track the cardiovascular tests on each participant from beginning to end?
- What would I expect would be most likely to change in the software in the future?
- Would the software be applicable to other clinical studies happening at the MRC or in other research groups?
I tried to recall what my 10 years in clinical trial work had taught me. I had worked in various capacities for both large and small clinical trials. Whatever the trial, there was always disparate bits of information that needed to be followed and completed. The trial always had a main entry form for completion, which was either paper or electronic. However, other test data is always involved in clinical trials such as blood tests, drugs, physiologic testing results, etc. and these rarely had proper tracking within the main form.
The majority of these tests required processing of some kind, even if it was just sending the blood to the laboratory for results. The trial coordinator expected the data to be gathered, analysed, and reported without subsequent tracking forms either paper or electronic. This was always a source of delay because it was difficult to manage, especially if staff changed over during the trial period. Frequently there would be a change of staff since clinical trials can run over months or years. A new staff member often felt lost on what had been collected so far, and what still needed to be collected. Occasionally the major funding body for the trial would ask for updates on the data, which caused multiple staff to spend hours putting together interim reports.
Kevin had been involved with past software projects which generated data entry applications. He raised the concern that generating software applications from a model had benefits and costs. The main benefits were that the software could allow a non-programmer to add new features to the application, such as new activities and new steps. The cost was that the application would not work well if some activities were treated differently than others. For example, he asked whether the minimal amount of data needed to track ECHO tests was the same as the minimum data needed to track HRV.
I thought about his concerns and made a number of conclusions:
- The test processes or activities were completely independent of each other
- The steps for each process or activity appeared in a sequence but were otherwise unrelated to one another
- If I needed to track other kinds of data, I could manage them through other means
- I was confident that I could identify a minimal feature set because I had spent most of the previous year trying to log data by hand
- I did not need enter clinical notes, but a simple comment box for the participant would be usual. Simple notes could be left in the box in case there was a change of staff. These notes might just say ‘participant refused test’. This could potential stop any searches for ‘missing data’ in the future.
Kevin produced an initial prototype of the forms using Project35, an open source tool he developed which uses XML schemas to generate simple data entry forms.
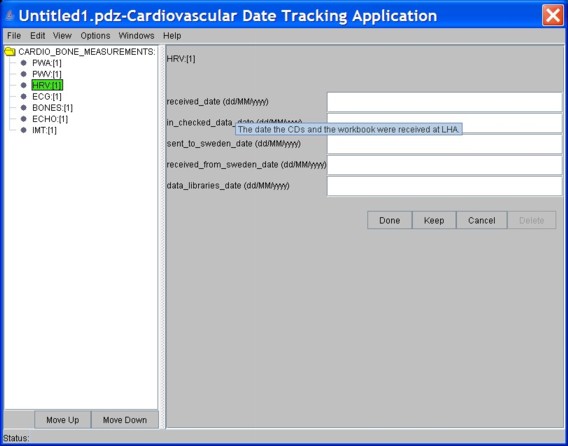
Kevin managed to produce the first basic prototype within a couple of months. Before I left the LHA in June 2009, I managed to check that the features were sufficient to electronically support the tasks I had done. I have greatly enjoyed making something that was simple, generic and useful. I have remained involved with the project in various capacities since my departure from the LHA.
Additional Contributions
Susan Latham, who was the line manager for the data services group, suggested that the application needed to support loading progress data about subjects from spreadsheets. She became more interested in the potential of using the tool within the DSG and with Di Kuh’s support, development continued.Tim Gaysin, who succeeded me in managing the data, later suggested that the tool should have the ability to simultaneously update a given activity step in a batch of subject member records. Imran Shah provided data sets which would test the application’s ability to import data.
Phil Curran, who became the next head of the DSG, worked with Kevin to develop validation routines to catch errors in imported spreadsheet data. Most recently, Andy Wong, Tim and Jane Abington suggested that the application needed to be able to produce tab-indented files which showed the progress of filtered subject members through specific activity steps.
The project continues.
Author: Sheila Raynor
(c)2010 Medical Research Council. Licensed under Apache 2.0.